In the vast world of movies, finding the perfect film to watch can be a daunting task. This is where recommendation systems come into play, making the process much smoother and enjoyable for users. This article will explore the concept of Content-Based Filtering for movie recommendations and demonstrate how to build and deploy a system using Streamlit.
Introduction
Recommendation systems are essential tools in the digital age, helping users discover content tailored to their preferences. Content-Based Filtering is one of the popular approaches, relying on the characteristics of items and user profiles. In the context of movies, it involves analyzing the content of films and suggesting similar ones based on certain features.
Understanding Content-Based Filtering
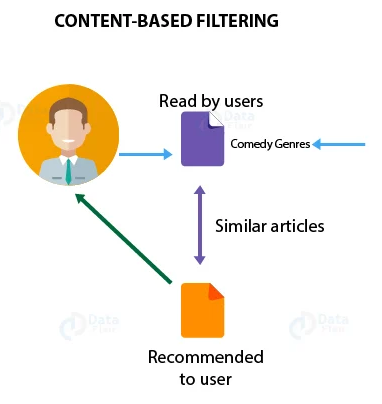
Content-Based Filtering relies on item features to make recommendations. In the case of movies, these features could include genres, actors, directors, and keywords. The system creates a profile for each user based on their preferences and recommends items that match those preferences.
TMDB 5000 Movie Dataset Overview
The TMDB 5000 Movie Dataset, sourced from Kaggle, comprises two CSV files: credits.csv and movies.csv. The movies file contains detailed information about movies, including titles, genres, and release dates. The credits file provides information about the cast and crew involved in each movie.
Building the Recommendation System
To implement Content-Based Filtering, we’ll use a dataset of movies and their features. Popular Python libraries like Pandas and Scikit-learn will be employed to preprocess the data and build a recommendation model. The key steps include:
1. Data Preprocessing: Cleaning and organizing the movie dataset.
In this case, the credits and movies datasets will be merged and replace the NaN values with empty strings.
# Merge 2 dataset
df_credits.columns = ['id','tittle','cast','crew']
df = df_movies.merge(df_credits, on='id')
# Replace NaN values in overview column with empty string
df['overview'] = df['overview'].fillna('')2. Vectorization: Transforming textual data into numerical vectors for machine learning.
tfidf = TfidfVectorizer(
min_df=3, # Ignore less common words
strip_accents='unicode', # Remove accents
ngram_range=(1,3), # Consider single words, pairs, and triplets
stop_words='english') # Exclude common English words
tfidf_matrix = tfidf.fit_transform(df['overview'])
tfidf_matrix.shape3. Similarity Calculation: Using cosine similarity to measure the similarity between movies.
cosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)4. Building the Recommendation Function: Creating a function that takes a movie as input and returns a list of similar movies.
Before we make the function, we need to set up a way that links movie titles to their positions in the DataFrame using its title by construct a reverse map of indices and movie title.
indices = pd.Series(df.index, index=df['title']).drop_duplicates()The recs function is a recommendation engine designed to offer movie suggestions based on a provided movie title. Leveraging a precomputed cosine similarity matrix cosine_sim, the function begins by identifying the index of the input movie title in the dataset. It then calculates the cosine similarity scores between the selected movie and all others in the dataset, sorting them in descending order.
def recs(title, cosine_sim=cosine_sim):
idx = indices[title]
similarity_scores = list(enumerate(cosine_sim[idx]))
similarity_scores = sorted(similarity_scores, key=lambda x: x[1], reverse=True)
similarity_scores = similarity_scores[1:11]
movie_indices = [i[0] for i in similarity_scores]
return df['title'].iloc[movie_indices]5. Saving Key Components to Pickle Files
To enhance efficiency in preparation for deployment, we can save essential components of our recommendation system as pickle files. These components include the dataset, cosine similarity matrix, and movie indices.
pickle.dump(df, open('movies_list.pkl', 'wb'))
pickle.dump(cosine_sim, open('similarity.pkl', 'wb'))
pickle.dump(indices, open('indices.pkl', 'wb'))Deploying with Streamlit
Streamlit is a user-friendly Python library for creating web applications with minimal effort. We’ll use Streamlit to turn our recommendation system into an interactive web app. The steps include:
1. Installing Streamlit
pip install streamlit2. Creating the App: Designing the user interface and integrating the recommendation function including the TMDB API.
For this script, we have three files that we saved previously to load. The cosine similarity matrix is loaded from pickle files, and movie data, such as titles and indices, is extracted from the relevant files. Additionally, we have a function to retrieve movie poster image URLs from The Movie Database (TMDb) API.
def fetch_poster(movie_id):
# API request to retrieve movie information
url = "https://api.themoviedb.org/3/movie/{}?api_key=a3cdfdc415ae12dc0ce1e65d46678daf&language=en-US".format(movie_id)
data = requests.get(url)
data = data.json()
# Extracting poster path from API response
poster_path = data['poster_path']
full_path = "https://image.tmdb.org/t/p/w500/" + poster_path
return full_path3. Launching the App: Running the Streamlit app locally for testing.
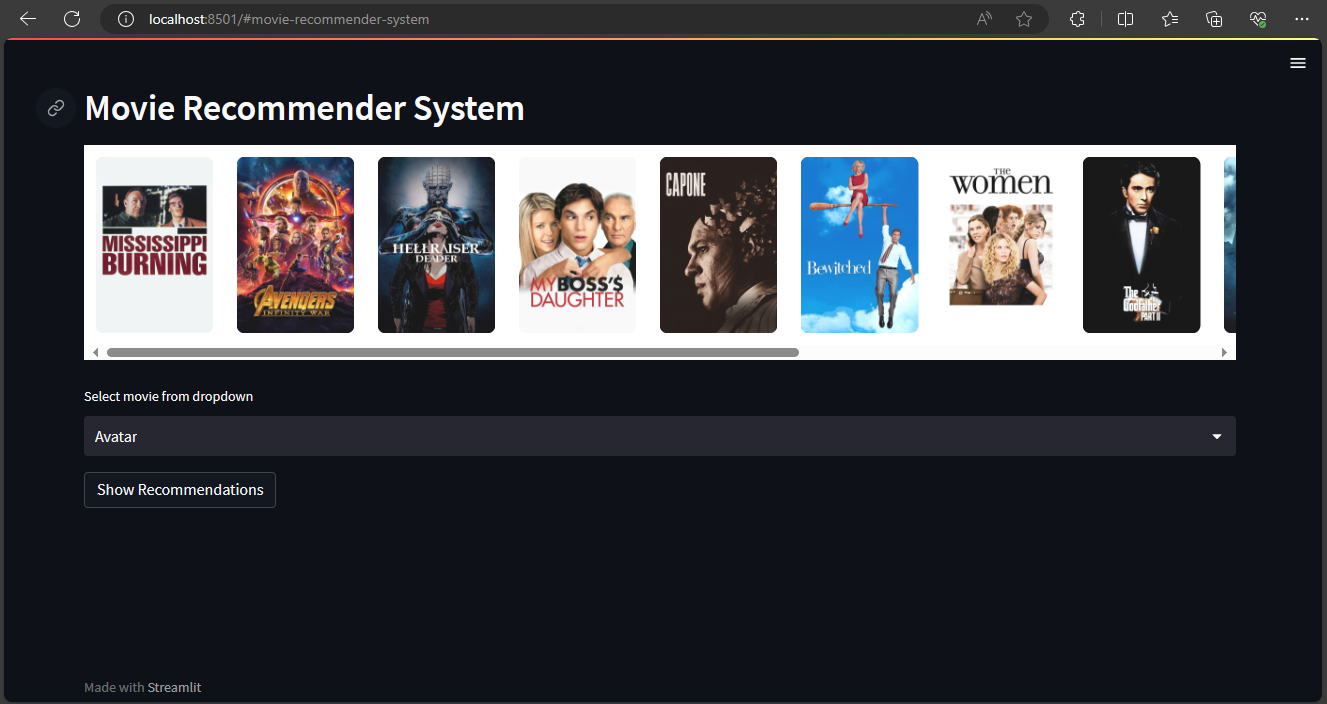
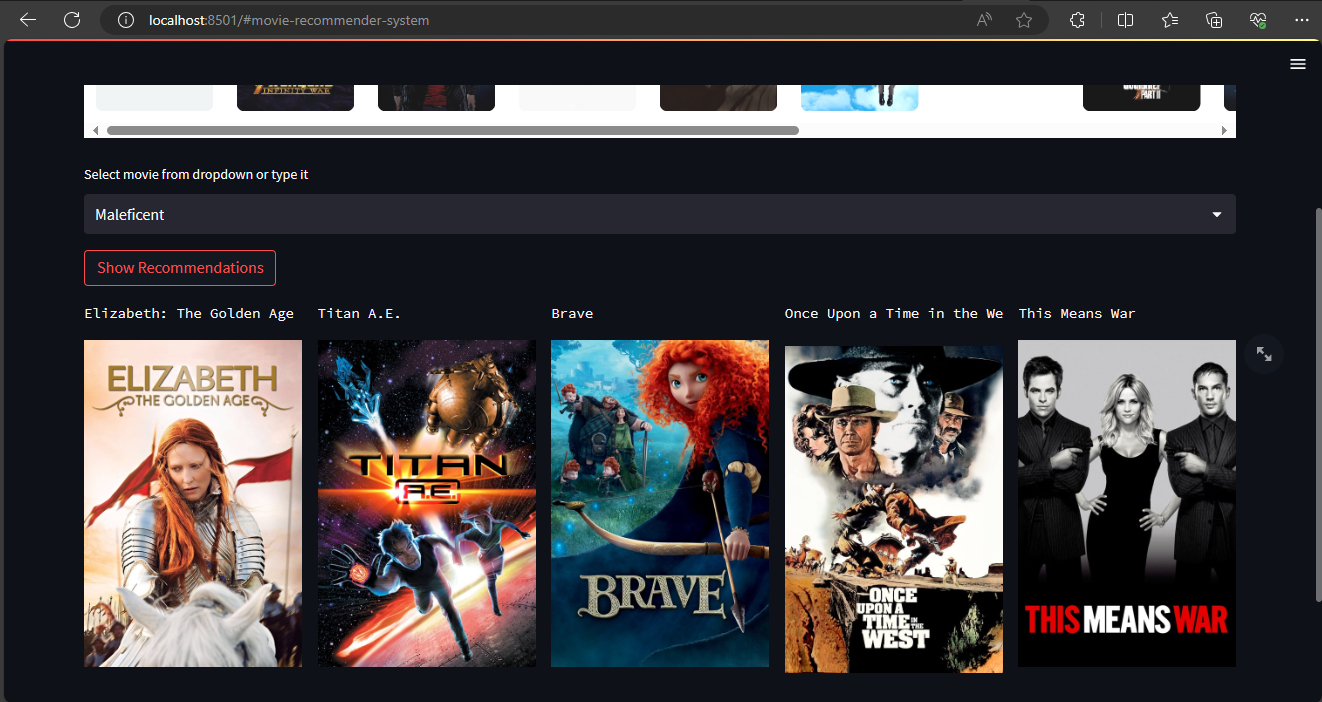
streamlit run app.pyOn the website, users can either choose a movie from the dropdown list or manually type it. Upon clicking the Show Recommendations button, the application presents five movie recommendations based on the similarity to the user’s selection. Each recommendation includes the title and poster of the film, providing a visually enhanced experience for the user.
Conclusion
Building a movie recommendation system with Content-Based Filtering and deploying it with Streamlit can enhance user engagement and satisfaction. This article has provided a step-by-step guide to implement the recommendation system and turn it into an interactive web application. With this system in place, users can discover new movies that match their preferences, such as the movie titles they enjoy.
The github repo details
To use the repo there are several things to do:
- Unzip
dataset.zipandfrontend.zipfirst - Run movie recommendation notebook to generate
.pklfiles. - In the terminal run
streamlit run app.py