Introduction
In this British Airways Data Science Program, participants are invited to step into the shoes of a British Airways team member, gaining firsthand experience in tasks that mirror the daily endeavors of their Data Science team. From scraping customer review data to constructing predictive models, this program provides a unique opportunity to explore the captivating world of data-driven decision-making.
1. Web Scraping
In this notebook, I am tasked with extracting and exploring British Airways passenger reviews from the well-known travel review site, Skytrax. Through web scraping techniques with BeautifulSoup Python, I collected a dataset of 1,200 reviews, which offered a comprehensive glimpse of customer sentiment towards the airline.
Data Collection:
My scraping efforts were concentrated on the British Airways reviews page on Skytrax, capturing information across 12 pages, each containing 100 reviews. The result was a diverse dataset encompassing various aspects of passenger experiences.
Data Cleaning and Preprocessing:
To refine the quality of our dataset, I implemented a rule-based approach involving several preprocessing steps. This included cleaning the text, tokenization, POS tagging, removal of stopwords, and lemmatization. The goal was to transform the raw reviews into a format suitable for sentiment analysis.
Sentiment Analysis with VADER:
I employed VADER, a potent sentiment analysis tool, to evaluate the emotional tone of each review. The compound sentiment score provided by VADER allowed me to categorize reviews as positive, negative, or neutral. The sentiment analysis revealed that 51.4% of reviews were positive, 37.7% were negative, and 10.9% were neutral.
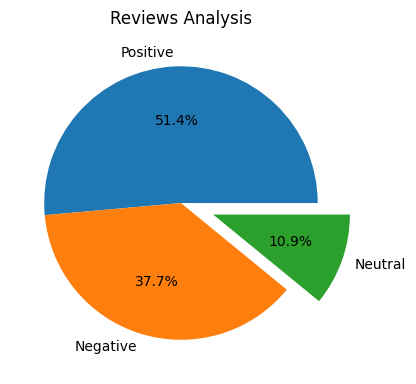
Key Findings:
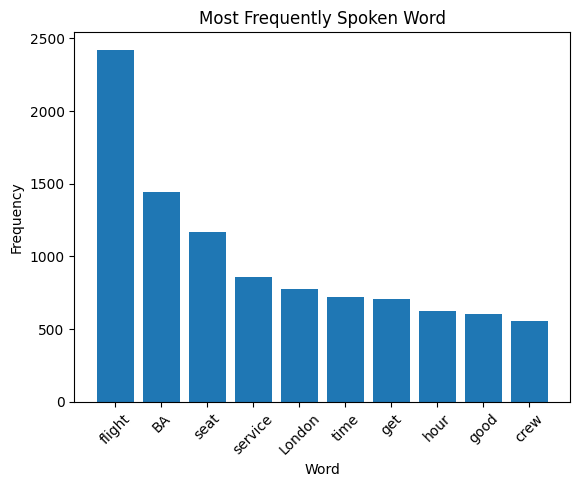
- Most Frequent Words: My analysis of frequently spoken words unveiled insights into the topics discussed by passengers. The top words included “flight,” “BA,” “seat,” “service,” “London,” and others, shedding light on crucial aspects of passenger experiences.
- Wordcloud Visualization: To offer a visually appealing representation of the dataset, I generated a wordcloud. This visualization highlighted the prominent terms, providing a quick overview of the most prevalent words in the reviews.

Conclusion:
My exploration into British Airways reviews using web scraping and sentiment analysis illuminated the diverse range of passenger experiences. By leveraging Python’s powerful tools, I not only collected a substantial dataset but also gained valuable insights into customer sentiments. Such analyses can be instrumental for airlines in identifying areas of improvement and maintaining high standards of customer satisfaction.
Dataset Availability:
The cleaned and processed dataset, along with sentiment analysis results, has been saved to a CSV file named BA_reviews.csv This file serves as a valuable resource for further analyses and can be utilized for ongoing monitoring of customer sentiments.
2. Making Predictive Models
Exploratory Data Analysis (EDA):
I began by conducting EDA to gain insights into the dataset’s statistical properties. The dataset, containing 50,000 entries and 14 columns, showcased information on passenger details, booking preferences, and flight characteristics. Fortunately, there were no null values in the dataset.
Data Preprocessing:
To prepare the data for modeling, I converted categorical columns into numerical formats using factorization. Subsequently, I performed mutual information analysis, identifying the most influential features related to booking completion. The top six features included route, booking origin, flight duration, wants extra baggage, length of stay, and number of passengers.
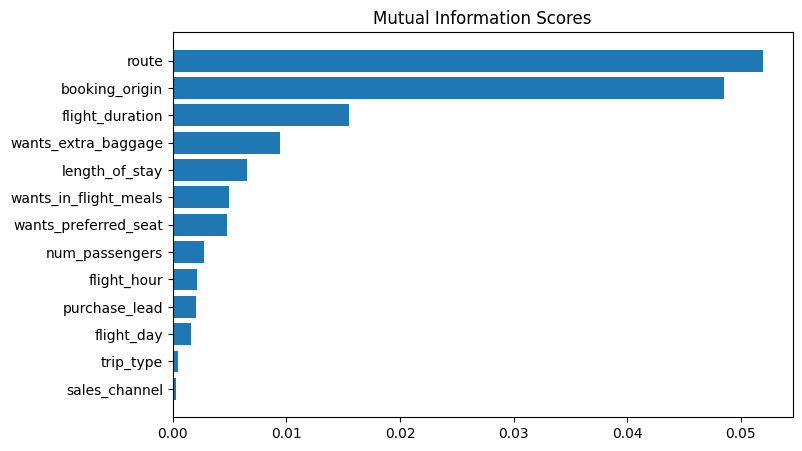
Model Building:
I implemented predictive models using Logistic Regression and XGBoost classifiers. Two variations of each model were considered: one utilizing only the top six features and another incorporating all available features. The performance metrics, including accuracy and AUC score, were used to assess model effectiveness.
Model Results:
- Logistic Regression:
- Model 1 (Top 6 Features): Accuracy - 84.58%, AUC Score - 0.5233
- Model 2 (All Features): Accuracy - 84.79%, AUC Score - 0.5074
- XGBoost Classifier:
- Model 3 (Top 6 Features): Accuracy - 84.79%, AUC Score - 0.5232
- Model 4 (All Features): Accuracy - 84.96%, AUC Score - 0.5432
Final Model Selection:
The XGBoost classifier with all features emerged as the optimal model, demonstrating good accuracy and a higher AUC score compared to other models. This model was selected as the final predictive model for customer bookings.
Validation with Test Data:
The finalized XGBoost model was validated using a test dataset, resulting in an accuracy of 85.19% and an AUC score of 0.5404. These metrics affirmed the model’s robustness and reliability in predicting customer booking outcomes.
Conclusion:
Through exploratory data analysis, feature engineering, and model building, this notebook successfully navigated the process of predictive modeling for customer bookings. The selected XGBoost model with all features proved effective in forecasting booking completions, showcasing its potential application in real-world scenarios for optimizing booking processes and enhancing customer satisfaction.